Zhuoyun Du | 杜卓耘
I am a second-year master's student in Computer Science at Zhejiang University. I currently work with Prof. Wei Chen at ZJUVAI within the State Key Laboratory of CAD&CG. I am also interning with the Taowise team at Alibaba.
Previously, I received my Bachelor's degree from Jinan University. I also served as a research assistant on the
ChatDev project  at
Tsinghua University,
advised by Prof. Zhiyuan Liu and
Prof. Chen Qian.
at
Tsinghua University,
advised by Prof. Zhiyuan Liu and
Prof. Chen Qian.
Seeking Ph.D. positions (Fall 2027).
Open to collaborations & recommendations!
Research Focus: Designing LLM-based autonomous agents that collaborate effectively to tackle complex tasks (software development, self-evolution, and latent-space reasoning).
News & Timeline
- 2025.11 Released Online-PVLM: Training-free framework for scalable personalized VLMs.
- 2025.11 Released Interlat: Direct inter-agent communication in latent space.
- 2025.10 EvoPatient open-sourced!
- 2025.08 Released SSPO: Pluggable RL process supervision framework.
- 2025.05 Two papers accepted at ACL 2025!
- 2024.12 Scaling MAS accepted at ICLR 2025!
- 2024.12 Introduced EvoPatient. arXiv
- 2024.09 Paper on information asymmetry accepted at NeurIPS 2024.
Selected Publications
(† denotes equal contribution)
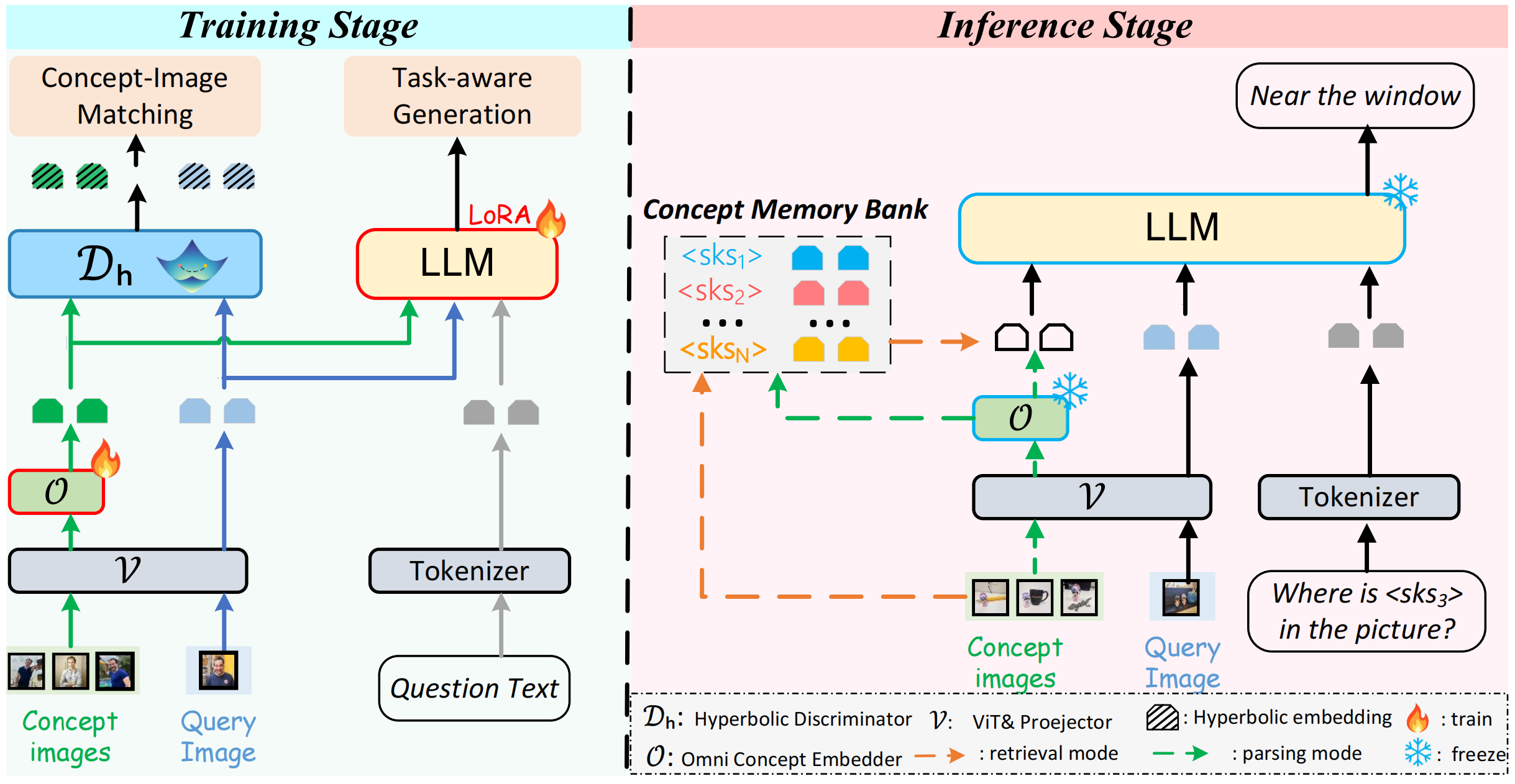
Online-PVLM: Advancing Personalized VLMs with Online Concept Learning
@article{bai2025onlinepvlm,
title={Online-PVLM: Advancing Personalized VLMs with Online Concept Learning},
author={Bai, Huiyu and Wang, Runze and Du, Zhuoyun and Zhao, Yiyang and Zhang, Fengji and Chen, Haoyu and Zhu, Xiaoyong and Zheng, Bo and Zhao, Xuejiao},
journal={arXiv preprint arXiv:2511.20056},
year={2025}
}
Enabling Agents to Communicate Entirely in Latent Space
@article{du2025interlat,
title={Enabling Agents to Communicate Entirely in Latent Space},
author={Du, Zhuoyun and Wang, Runze and Bai, Huiyu and Cao, Zouying and Zhu, Xiaoyong and Zheng, Bo and Chen, Wei and Ying, Haochao},
journal={arXiv preprint arXiv:2511.09149},
year={2025}
}
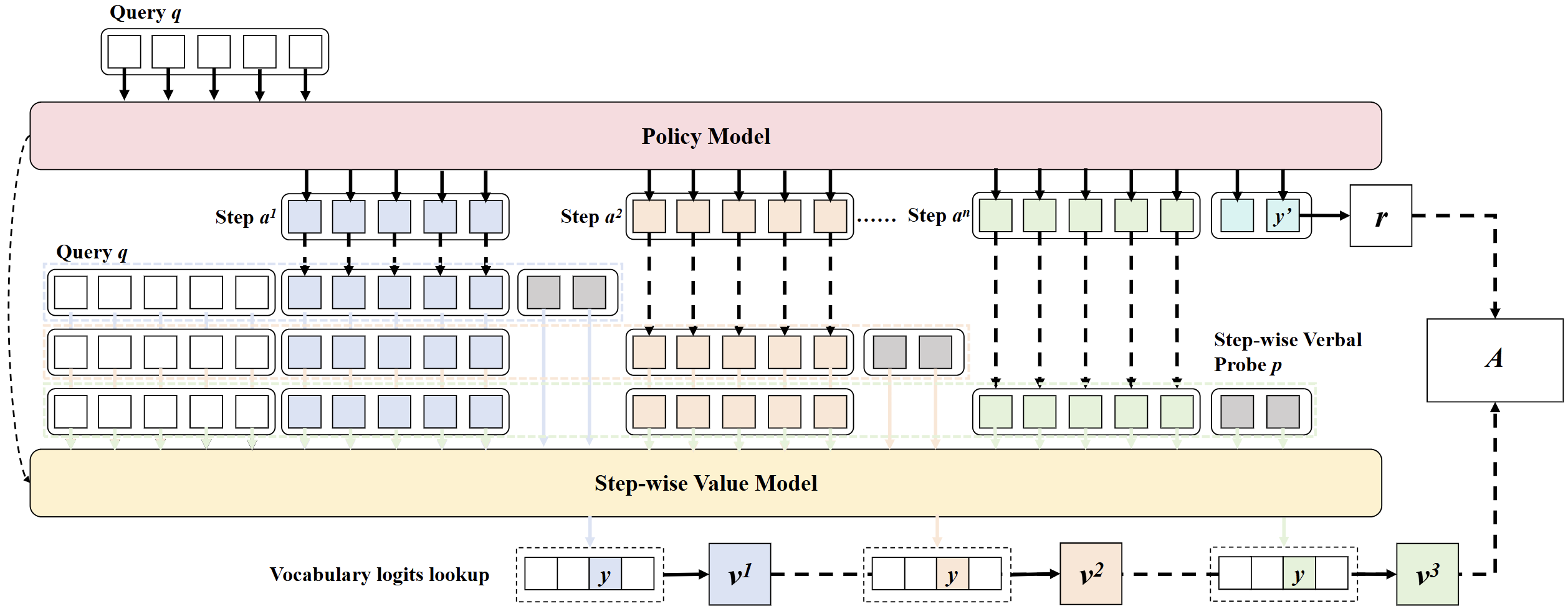
SSPO: Self-traced Step-wise Preference Optimization for Process Supervision and Reasoning Compression
@article{xu2025sspo,
title={SSPO: Self-traced Step-wise Preference Optimization for Process Supervision and Reasoning Compression},
author={Xu, Yuyang and Cheng, Yi and Ying, Haochao and Du, Zhuoyun and Hu, Renjun and Shi, Xing and Lin, Wei and Wu, Jian},
journal={arXiv preprint arXiv:2508.12604},
year={2025}
}

LLMs Can Simulate Standardized Patients via Agent Coevolution
@article{du2024evopatient,
title={LLMs Can Simulate Standardized Patients via Agent Coevolution},
author={Du, Zhuoyun and Zheng, Lujie and Hu, Renjun, et al.},
journal={arXiv preprint arXiv:2412.11716},
year={2024}
}
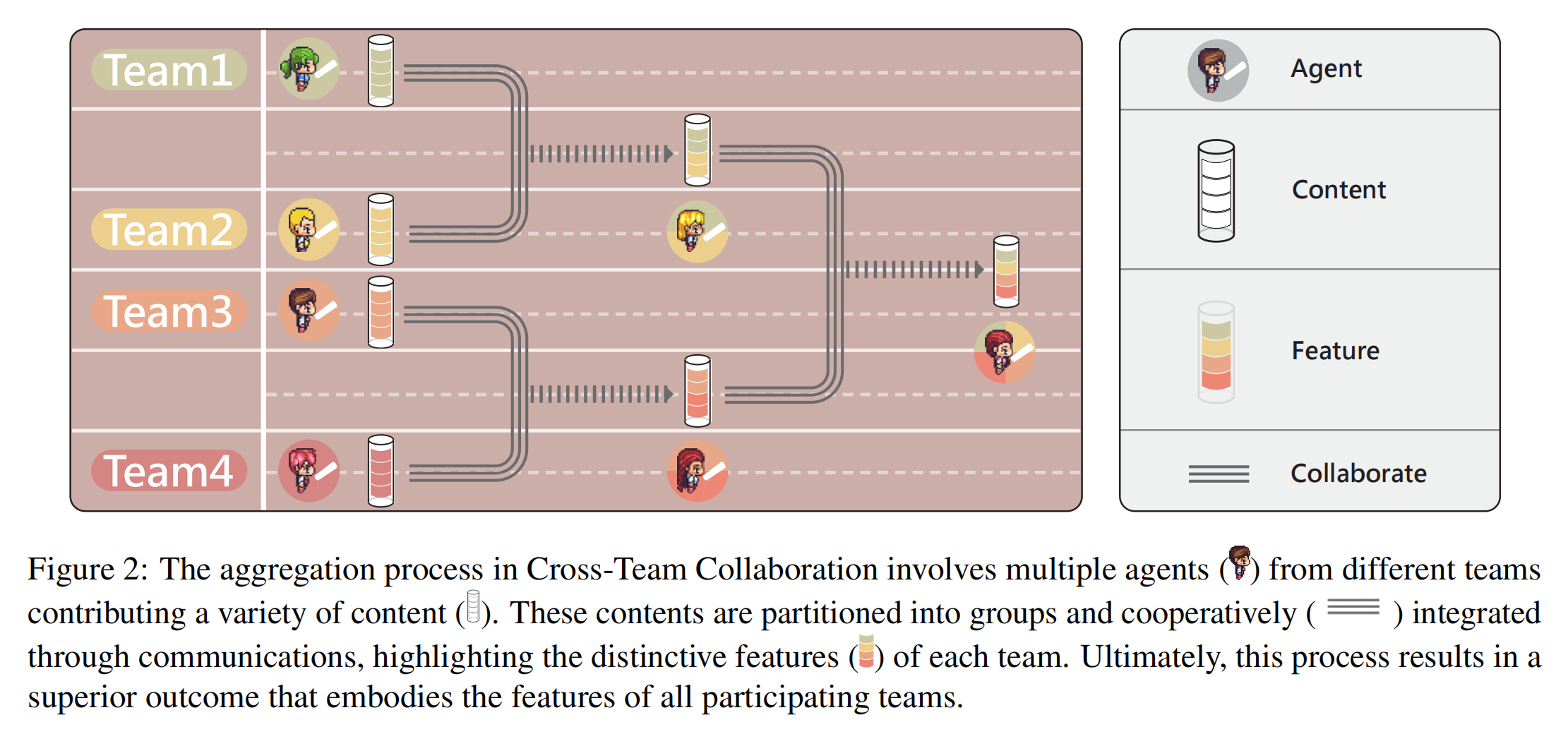
Multi-Agent Collaboration via Cross-Team Orchestration
@article{du2024crossteam,
title={Multi-Agent Software Development through Cross-Team Collaboration},
author={Du, Zhuoyun and Qian, Chen and Liu, Wei, et al.},
journal={arXiv preprint arXiv:2406.08979},
year={2024}
}
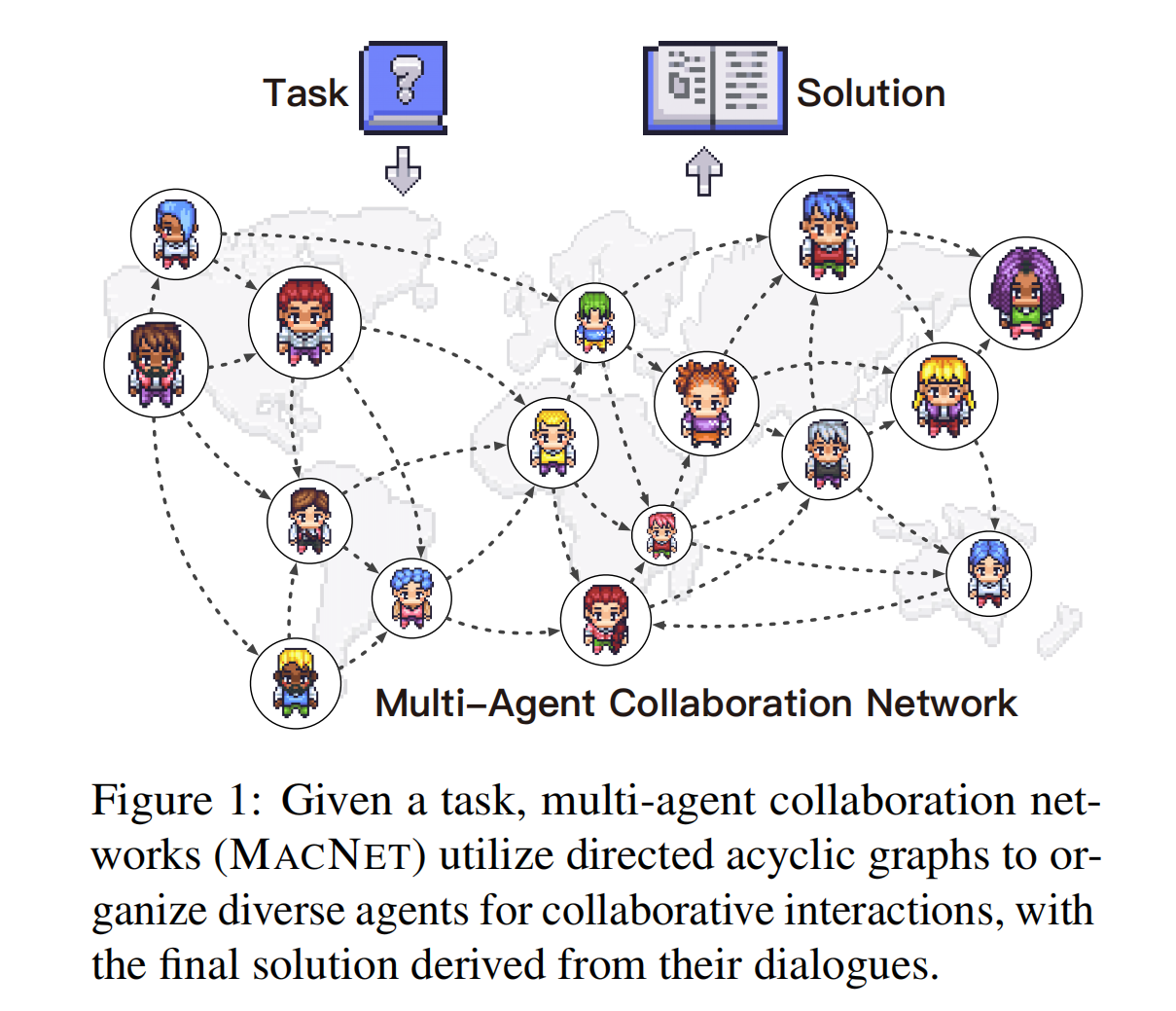
Scaling Large-Language-Model-based Multi-Agent Collaboration
@article{qian2024scaling,
title={Scaling Large-Language-Model-based Multi-Agent Collaboration},
author={Qian, Chen and Xie, Zihao and Wang, Yifei, et al.},
journal={arXiv preprint arXiv:2406.07155},
year={2024}
}

Autonomous Agents for Collaborative Task under Information Asymmetry
@article{liu2024autonomous,
title={Autonomous Agents for Collaborative Task under Information Asymmetry},
author={Liu, Wei and Wang, Chenxi and Wang, Yifei, et al.},
journal={arXiv preprint arXiv:2406.14928},
year={2024}
}
Experience
Taowise @ Taotian (Alibaba Group)
Focusing on research on new paradigm in multi-agent latent space reasoning/communication enhancement and supervised fine-tuning (SFT) methodologies for LLMs.
THUNLP @ Tsinghua University
Deeply involved in the development of the ChatDev project and related works, focusing on multi-agent cross-team collaboration.
Projects
Multi-Agent Research Interactive E-book
A comprehensive collection of research papers on LLM-based multi-agent systems presented in an interactive e-book format. Organizes cutting-edge research into task-solving-oriented and social-simulation-oriented systems, covering agent communication, organizational structures, and co-evolution mechanisms.
 and its extended branches, serving as the leader for one key branch.
and its extended branches, serving as the leader for one key branch.
Awards & Honors
- 2025 National Scholarship Top 0.2%
- 2025 Outstanding Student Scholarship
- 2024 First-Class Scholarship (Outstanding Graduate Student Award)
- 2023 Second-Class Scholarship
- 2022 Second-Class Scholarship
Academic Service
Program Committee / Reviewer:
NeurIPS 2025
ICLR 2026
Beyond Research
Visit my Personal Blog for research insights, photography, and life experiences.
(I will try to update more frequently :D)